
Often information is not available in a computer readable format like JSON, XML or CSV. When only a human readable PDF file is available, one can try to use a PDF parser to retrieve the needed information. There is e.g. Apache Tika that can read PDF files and return the contents as tokens. It can be quite useful but it doesn’t return tabular information so if you have a table with empty cells you don’t see which cells are empty and it can be difficult to know to which cell the returned data belongs to.
For this purpose another library called Tabula exists. It provides an easy to use local web page that allows to the tables of a PDF file and export them as CSV or JSON files:
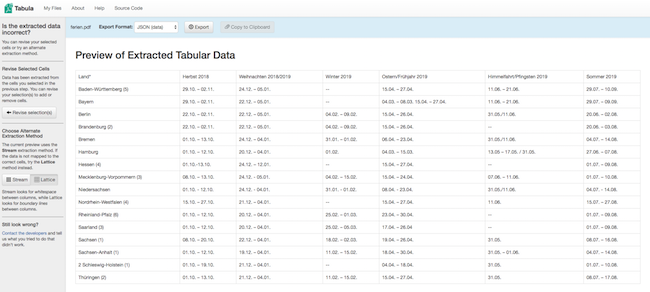
You can also embed tabula-java into an own program to use it e.g. in batch jobs. E.g. this Kotlin snippet loads a PDF file pdfFile and writes its contents as JSON into tmpfile:
val tmpfile = File.createTempFile("pdfparser", "json")
val args = arrayOf(pdfFile.absolutePath, "-g", "-l", "-f", "JSON", "-o", tmpfile.absolutePath)
val parser = DefaultParser()
val cmd = parser.parse(CommandLineApp.buildOptions(), args)
val stringBuilder = StringBuilder()
CommandLineApp(stringBuilder, cmd).extractTables(cmd)
From there you can parse the JSON to process it further.